Study Overview
Identifying highly dynamic actions from video is a complicated task in visual recognition, with applications ranging from automatic video tagging to collision avoidance systems. Humans display almost full range of motion through dance, so identifying dance styles is an excellent case study for testing human motion identification methods.
Our project is an action recognition task which seeks to classify video clips as one of ten types of dance: ballet, break dancing, flamenco, foxtrot, latin, quickstep, square, swing, tango, or waltz. For this task, we use the Let’s Dance dataset presented by Castro et al., which is comprised of 10-second video clips from YouTube. Some of these video clips occur in very similar settings, which makes them challenging to differentiate based on background imagery alone. For example, the dances below (tango, waltz, and foxtrot) are very difficult to distinguish.

As a result, a successful model will need to encode movement or pose information. We assess the effectiveness of several sequential models, including a traditional LSTM, in modeling dynamic movement. We find that, although these models achieve significantly better performance than the baseline frame-by-frame approach, they don’t achieve the accuracy of Castro’s temporal models.
Approach
Baseline
The traditional baseline method for action classification from video is a spatial model—that is, a frame-by-frame model with no temporal component. A CNN is trained on individual frames of a video. At test time, all frames of a video are individually classified, and the video’s final classification is the majority class of its frames. We compare our results to the frame by frame model introduced by Castro et al., which uses a pre-trained variant of CaffeNet that has been finetuned on the Let’s Dance dataset. This model achieves test accuracy of 56.4%.
Sequential Models
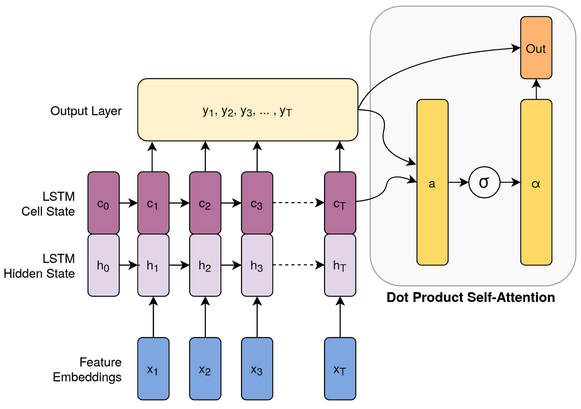
Like Castro et al., our method utilizes a two-stream late fusion model, shown in the figure at the top of the page. The two streams of data are RGB images and PoseNet skeleton data. Features are extracted from each RGB frame using Pytorch’s pretrained ResNet-18 model with the final layer converted to an identity layer, resulting in 512-dimensional features. Features are extracted from the PoseNet data using a shallow CNN with small filters adapted from Khalid and Yu (2019). The two streams of features are then concatenated.
To create sequences from these features, we subsample the original 30fps video clips, with the subsampling rate determined through hyperparameter tuning. This creates a sequence of length anywhere between 2 and 300 for each 10-second clip. This sequence of combined data is then input to one of three sequential models: an LSTM, an LSTM with self-attention, and a temporal convolutional neural network (TCN) from Bai et al..
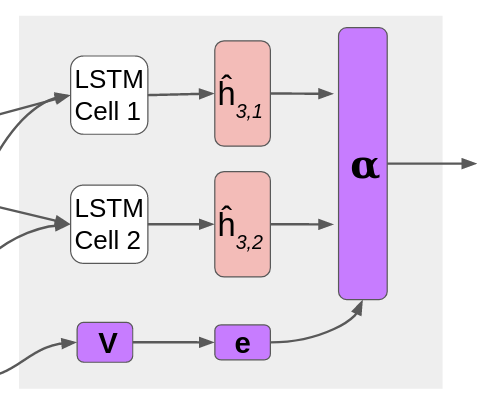
In our LSTM, the addition of self-attention allows the model to determine which frames in a sequence should receive the most weight in the output. The attention mechanism used is scaled dot product self-attention, adapted from Vaswani et al. (2017). The authors advocate for using self-attention as opposed to the recurrent and convolutional layers commonly used for attention because it is computationally less complex and faster to compute. Self-attention also yields more interpretable models. The architecture is shown below.
We chose the TCN because, unlike RNNs, it doesn’t suffer from the vanishing gradient problem; the gradient flows back through the convolutional layers of the TCN, rather than back through the sequence. The TCN also has many fewer parameters than even a single layer LSTM. The structure of the TCN is shown below.
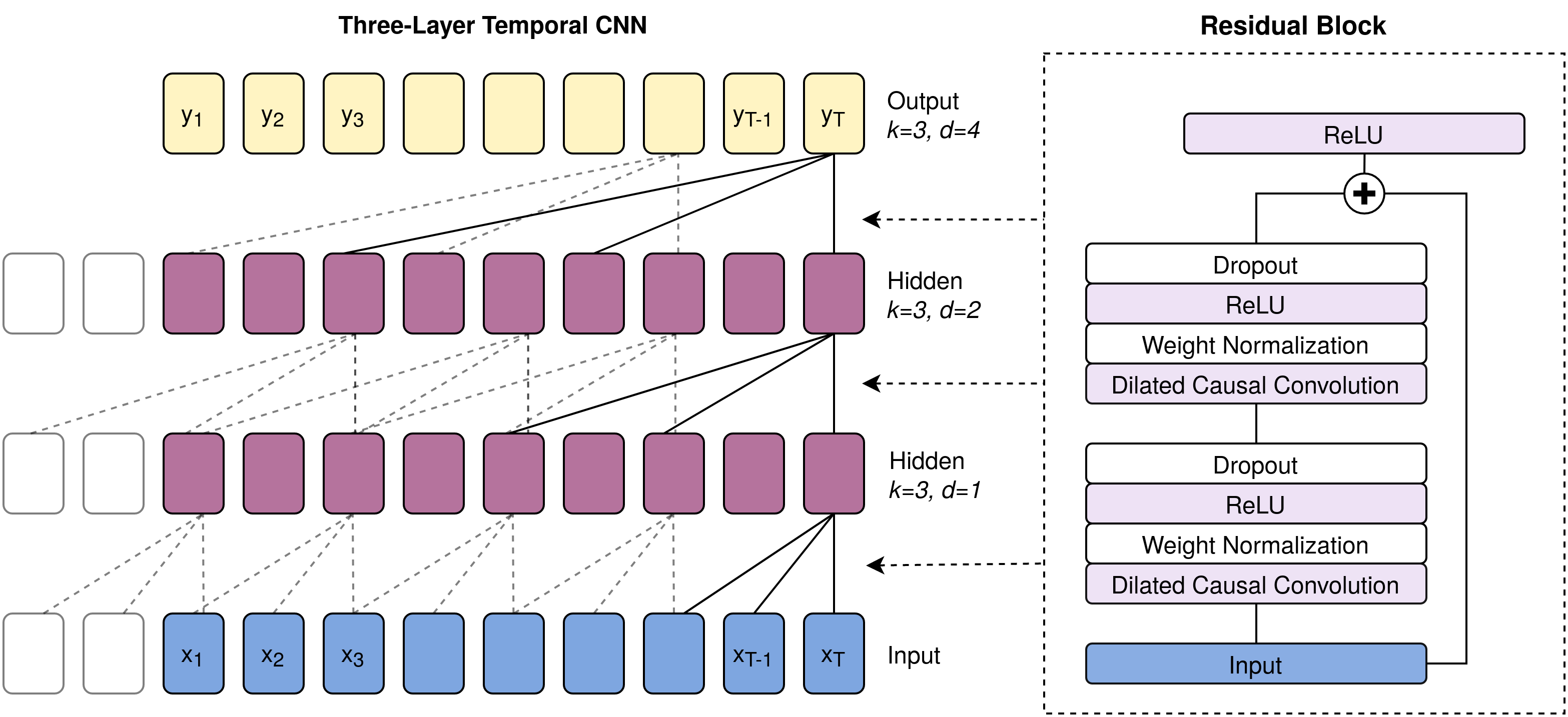 Architecture of a TCN. The left-hand side shows a three-layer TCN with kernel size 3 and exponential dilation in each layer. The right-hand side shows the detail of each layer, including two dilated causal convolutions and a residual connection. Based on Figure 1 from Bai et al..
Architecture of a TCN. The left-hand side shows a three-layer TCN with kernel size 3 and exponential dilation in each layer. The right-hand side shows the detail of each layer, including two dilated causal convolutions and a residual connection. Based on Figure 1 from Bai et al..
Experiments
Data
The Let’s Dance video dataset by Castro et al. contains roughly 1,000 videos spanning 10 dynamic and visually overlapping dance types. There are approximately 100 videos per dance style, extracted from YouTube in 10-second clips at 30 frames per second. Each video is available in its original RGB format and as extracted pose coordinates.
The data was randomized at the video level into 80% training, 10% validation, and 10% test data. The same splits were used for the RGB data and the pose data.
Results
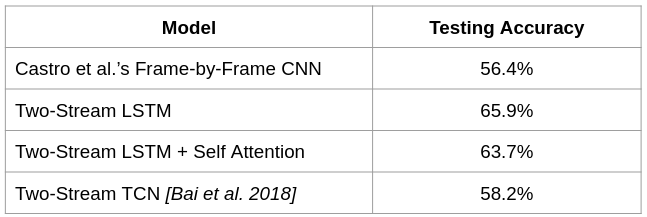
Our quantitative results, relative to the frame-by-frame baseline from Castro et al., are shown in the table below. Although the frame-by-frame model is the most relevant, it is not a perfect comparison. Castro’s frame-by-frame model makes predictions for every frame in a given video clip, and then uses plurality voting to classify the video as a whole. In contrast, our sequential models use frame sub-sampling to reduce the length of the input sequence, so less information is used for training. Furthermore, all of our models utilize the extracted pose information, which Castro’s frame-by-frame baseline does not.
Analysis
LSTM
The LSTM model achieves testing accuracy of 65.9%, ten percentage points higher than the baseline frame-by-frame model. However, the accuracy is still several percentage points behind Castro’s multi-stream CNNs that incorporate optical flow.
The dropout rate used to train this model is 0.70; because the data set is so small (less than 1,000 video clips in total), even a small model can be expressive enough to over-fit the training data. Therefore, aggressive dropout is needed to ensure that the model generalizes to the test data.
Surprisingly, the hyperparameter tuning chose sub-sampling of every 60 frames, meaning that each 10-second video clip was reduced to a sequence of 5 frames, one every two seconds. This level of sub-sampling is surprising because it can’t encode dance movements faster than two seconds. On the other hand, it’s likely that processing very short sequences greatly reduced or eliminated the vanishing gradient problem.
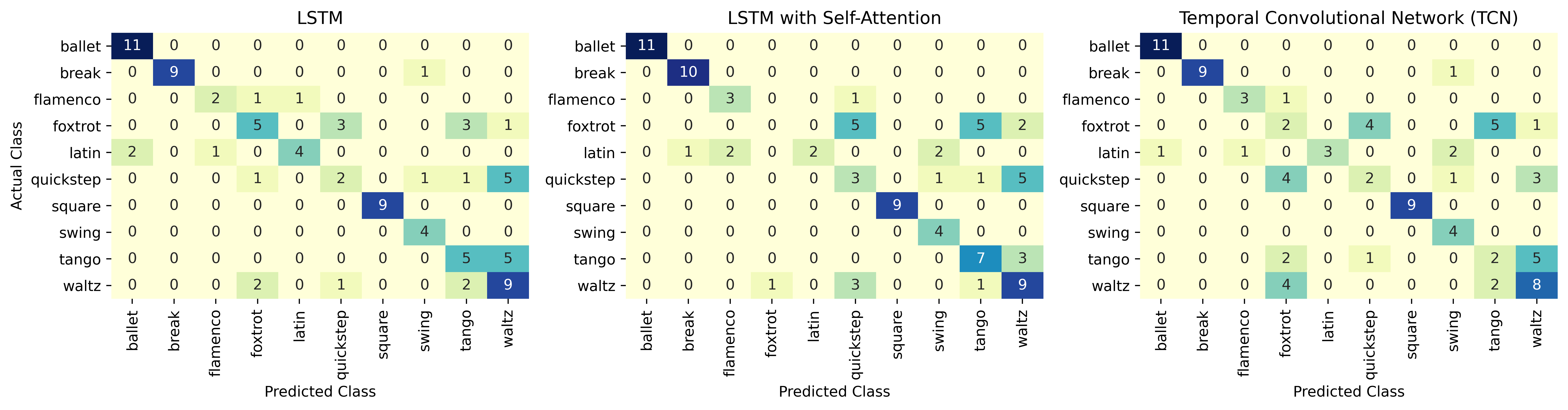
The figure above shows the confusion matrix for each model. The dance styles predicted with the greatest accuracy are ballet, break dancing, and square dancing. Ballet and break dancing, unlike the other dance forms, are not partner dances, so they are visually distinctive. Although square dancing is a partner dance, large portions of the dance are performed in groups, for example by joining hands in a circle. This may explain why square dancing is always correctly identified, and is never confused with other dance forms. The highlighted area in the bottom right corner of the confusion matrix indicates that tango and waltz are often confused; of the ten tango videos, half were mistakenly classified as waltz.
LSTM with Self-Attention
We expected self-attention to enhance the performance of the LSTM by directing weight to the most important frames. However, the LSTM with attention achieves accuracy of 63.7%, slightly lower than the standard LSTM. Given that our test data set only consists of 91 video clips (10% of the original ~1000 videos), this performance is comparable. The confusion matrix is similar to the confusion matrix for the LSTM. Relative to the plain LSTM, however, it is more successful at differentiating tango and waltz; perhaps the attention mechanism was useful in differentiating visually similar ballroom dances. There were no dance types where the TCN outperformed both LSTM models in identifying the right videos.
Even though classification accuracy was comparable between the LSTM model and the LSTM with attention model, hyperparameter tuning yielded pretty different parameters. While hyperparameter tuning chose a very aggressive dropout rate for the LSTM, it selected a dropout rate of 0.05 for the self-attention model. Also, it preferred a smaller frame subsampling rate of every 30 frames for the self-attention model, meaning that each 10-second video clip was reduced to a sequence of 10 frames (one per second). This yields a sequence with double the number of frames as compared to the LSTM. Perhaps a smaller sampling rate was preferred because the attention model is able to handle longer sequences of frames since it can upweight more important frames and downweigh less important ones.
Temporal Convolutional Network (TCN)
The TCN model achieves accuracy of 58.2% on the test data, only marginally better than the frame-by-frame model. Although the TCN performed well on the validation set, achieving 75% accuracy, it did not generalize well to the test data. The confusion matrix shows that, like the LSTM models, the TCN performs well on ballet, break dancing, and square dancing, likely due to the distinctive features of those dances. However, it struggled more than the LSTM models in identifying the tango videos, instead mislabelling most of them as waltz.
One hypothesis for the TCN’s subpar performance is that it is not expressive enough to capture differences in movement between the dances; the LSTM models involve far more parameters per layer than the TCN. Perhaps if we had increased the complexity of the TCN by adding hidden layers, reducing the regularization, etc. its performance would have improved.
Discussion
Surprisingly, the plain LSTM model out-performed both the LSTM with attention and the TCN model. We had expected that attention would help direct the focus to key frames, and that the TCN would alleviate potential problems with vanishing gradients. However, given that the LSTM performed best with only 5 frames from a 10-second video clip, vanishing gradients were not problematic.
For this project, we chose not to use optical flow to encode the temporal dimension in order to determine how much a sequential model could capture on its own. However, we realized that optical flow is an important driver in the success of action recognition on highly dynamic motion. Given more time, we would set up a pipeline to process the videos’ optical flow data and expand our models to be three-stream.
Ultimately, one of the biggest constraints was the limited data set. Since there were only around 1,000 videos in total, the validation set and test set each only contained 100 observations. Castro \etal circumvented this problem by processing videos in 16-frame chunks, but we opted to use each video clip as a single input to our sequential models. Therefore, an important direction for future work is to use data augmentation to increase the data set size. Future work could also accommodate this smaller dataset by exploring alternative regularization strategies,such as normalization layers for the LSTM models.

 Download Final Deliverable
Download Final Deliverable